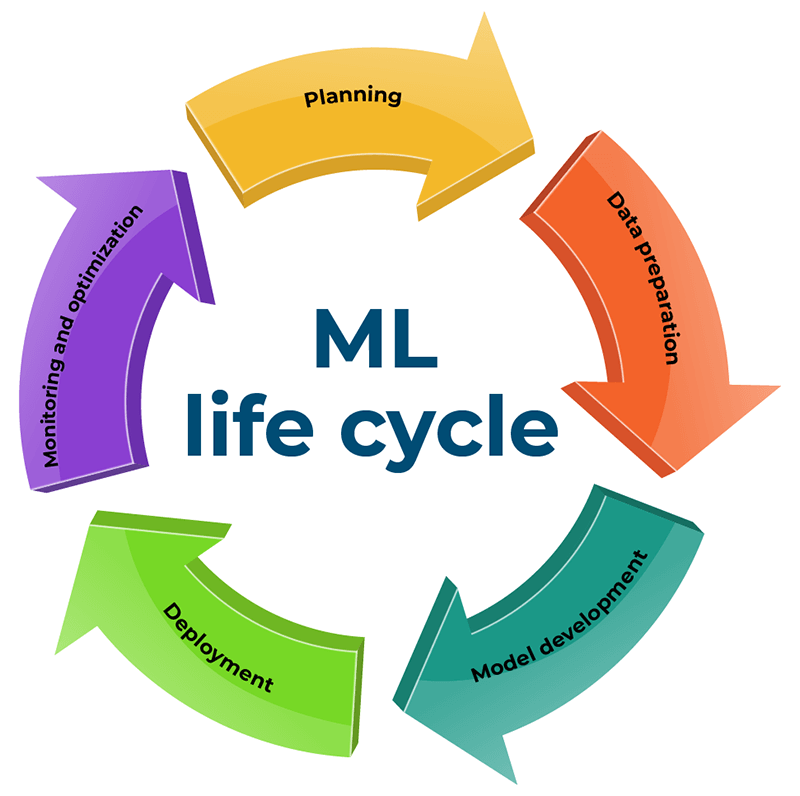
Embarking on constructing and utilizing a machine learning (ML) model is a nuanced endeavor demanding meticulous planning and dedicated effort. This intricate process unfolds through five pivotal stages within the machine learning life cycle, each with critical considerations. A comprehensive grasp of this life cycle empowers data scientists to allocate resources and gain immediate insights into their progression adeptly. Within this article’s confines, we delve into the quintessential stages – encompassing planning, data preparation, model construction, deployment, and monitoring – offering a detailed exploration of their significance in machine learning.
The significance of a framework in the ML life cycle
The Machine Learning life cycle orchestrates the strategic integration of artificial intelligence and machine learning, charting a course from project conception through model development to the critical junctures of monitoring and optimization. Beyond the customary narrative, this dynamic journey unfolds with the singular aim of addressing specific problems by deploying an ML model. However, diverging from conventional perspectives, it underscores the persistent need for post-deployment vigilance, emphasizing ongoing optimization and maintenance as indispensable safeguards against model degradation and the insidious encroachment of bias.

Phases of Machine Learning development
Embarking on the journey of machine learning development requires a keen exploration of its nuanced life cycle, comprised of five pivotal stages.
Pioneering planning
At the genesis of every model development expedition lies a crucial planning phase. This stage involves meticulously unraveling the identified problems with a discerning eye on resource efficiency. The roadmap to success encompasses the following:
In the initial phase of machine learning development, precision is paramount in defining the specific problem, whether addressing a sluggish customer conversion rate or a surge in fraudulent activities. Subsequently, the process demands the articulation of clear-cut objectives, outlining the desired outcomes, such as amplifying customer conversion rates or quelling fraudulent behavior. Carefully established metrics are applied for gauging success, with an accuracy rate of 70% deemed commendable, while achieving a rate between 70% and 90% is considered the epitome of success. This thoughtful and systematic approach to planning sets the foundation for a successful machine learning model development.
Data preparation
The second stage in machine learning development centers on the meticulous acquisition and refinement of data. Given the likelihood of dealing with a substantial volume of data, ensuring its accuracy and relevance becomes imperative before initiating the model-building process.
This pivotal data preparation stage unfolds through several integral steps. Initially, acquiring a substantial dataset is considered resource-intensive in Data Collection and Labeling, prompting exploration of existing data feasibility. Integration of data from diverse sources and the alternative of data collection through surveys, interviews, or observations are emphasized. Data labeling follows, assigning distinct labels to raw data like images, videos, or text, aiding categorization and future reference. Subsequently, Data Cleaning becomes paramount, with the dataset’s size correlating with the depth of required cleaning. Prudent removal of missing values and irrelevant information before model construction is highlighted for enhanced accuracy and reduced errors and bias. The culmination involves Exploratory Data Analysis (EDA), a pivotal step preceding model construction, scrutinizing the dataset through visualizations for a summarized overview, offering valuable insights into prevalent patterns and fostering a nuanced understanding among data scientists.
Model development
With prepared data in hand, the focal point shifts to model development, a pivotal phase in the machine learning life cycle, encompassing three key subpoints:
- Model selection and assessment: The critical step is choosing the model type. Data scientists fit and test various models to identify the one that outperforms the rest. Selection is typically based on the data’s nature, opting for a classification or regression model with the highest accuracy rate.
- Model training: Moving into the experimentation phase, data scientists input data into the chosen algorithm to extract initial outputs. This phase unveils the first glimpses of the final production, providing insights that guide modifications for improved predictions.
- Model evaluation: Upon completing the training phase, the final stage involves a comprehensive review, scrutinizing metrics like accuracy and precision to gauge the model’s performance. This assessment extends to a detailed analysis of errors and biases, enabling analysts to devise solutions for their elimination. If necessary, data scientists iteratively refine and rerun the model, incorporating enhancements to elevate accuracy and overall performance.
Deployment
The deployment phase integrates the developed model into an existing production environment, enabling informed business decision-making. The model deployment stage is one of the most challenging stages within the machine learning life cycle; model deployment often needs to be addressed due to the disparity between traditional model-building languages and the IT systems of many organizations. Consequently, data scientists frequently find themselves recoding models to align them with the production systems, necessitating a collaborative effort between data scientists and development (DevOps) teams.
Monitoring and optimization
In the culminating stages, continuous maintenance checks and periodic optimizations are imperative. As models may degrade over time, ensuring their sustained accuracy demands vigilant monitoring and optimization. Collaborative efforts between data scientists and most software engineers are usually pivotal, utilizing predictive analytics software to identify and rectify issues such as model drift or bias. Predictive analytics, leveraging data to discern industry trends and best practices, is vital in forecasting customer churn or tailoring marketing campaigns to engage potential interest.
Summing up
In conclusion, the machine learning life cycle stands as a fundamental framework, providing data scientists with a structured pathway for delving into the intricacies of machine learning model development. Guided by this comprehensive framework, the management of the ML model life cycle encompasses a holistic journey, commencing with the meticulous definition of problems and culminating in the continual optimization of the model. As a cornerstone for proficiency in machine learning, this life cycle framework encapsulates the essence of strategic and informed model development, facilitating a robust approach to solving complex problems and advancing the field of artificial intelligence.
OptScale, an open source MLOps and FinOps platform on GitHub offers complete transparency and optimization of cloud expenses across various organizations and features MLOps tools such as hyperparameter tuning, tracking experiments, versioning models, and ML leaderboards → https://github.com/hystax/optscale



