The art and science of hyperparameter tuning
- Edwin Kuss
- 6 min

What constitutes hyperparameter tuning?
Hyperparameter tuning is the process of finding the most effective combination of hyperparameters for a machine learning model. It’s a critical step in model development because the choice of hyperparameters — such as learning rate, number of layers, or batch size — can significantly impact model accuracy and performance.
There are different approaches to improving machine learning models, typically divided into model-centric and data-centric strategies. Model-centric tuning focuses on the structure and algorithms of the model itself, experimenting with different hyperparameter configurations to achieve better results. Data-centric optimization, on the other hand, improves model performance by enhancing the quality, balance, or volume of training data rather than changing the model.
One of the most widely used methods for hyperparameter optimization is grid search. In this approach, data scientists define a range of possible hyperparameter values, and the algorithm systematically tests all combinations to identify the best-performing setup. For example, tuning might involve evaluating a learning rate of 0.1 with one hidden layer versus two hidden layers to see which produces higher accuracy. This structured process helps identify the optimal hyperparameters and ensures the final model performs reliably across various datasets.
Exploring hyperparameter space and distributions
The hyperparameter space includes all possible combinations of hyperparameters that can be used to train a machine learning model. It can be imagined as a multi-dimensional space, where each dimension represents a specific hyperparameter. For example, if you’re tuning both the learning rate and the number of hidden layers, you’re exploring a two-dimensional space — one axis for each parameter.
Each hyperparameter also has a distribution, which defines the range of possible values and the probability of selecting them during tuning. This distribution helps determine how likely certain values are to be tested within the search process, guiding the optimization strategy.
The objective of hypertuning is to improve the model’s performance by systematically exploring this space and identifying the most effective combination of hyperparameters. The impact of hyperparameter distribution is equally important — it shapes how efficiently the algorithm searches for optimal values. Choosing the right distribution can significantly affect training time, convergence speed, and final model accuracy.
Types of hyperparameter distributions in machine learning and their role in ML optimization
In machine learning, probability distributions define how hyperparameter values are sampled during tuning. They determine both the possible range of values and the likelihood of selecting each one within the hyperparameter search space. Choosing the right distribution is essential for efficient model optimization and faster convergence.
Log-normal distribution
This distribution is used for parameters that take only positive values and may vary across several magnitudes, such as the learning rate. Because values are spread logarithmically, it captures skewed ranges more effectively and allows exploration over a broader scale.
Gaussian (normal) distribution
The Gaussian distribution is symmetrical around its mean and is suitable for parameters expected to vary slightly around an average value. It’s often used when tuning variables influenced by multiple small, random factors, such as dropout rates or weight initializations.
Uniform distribution
In a uniform distribution, every value within a specified range has an equal chance of being selected. This is ideal when there’s no prior knowledge about which range of values may work best, allowing a fair and unbiased search.
Beyond these, other probability distributions like exponential, gamma, and beta distributions are also used in machine learning. The choice of distribution directly affects how effectively hyperparameter tuning explores the search space — influencing both model performance and training efficiency.
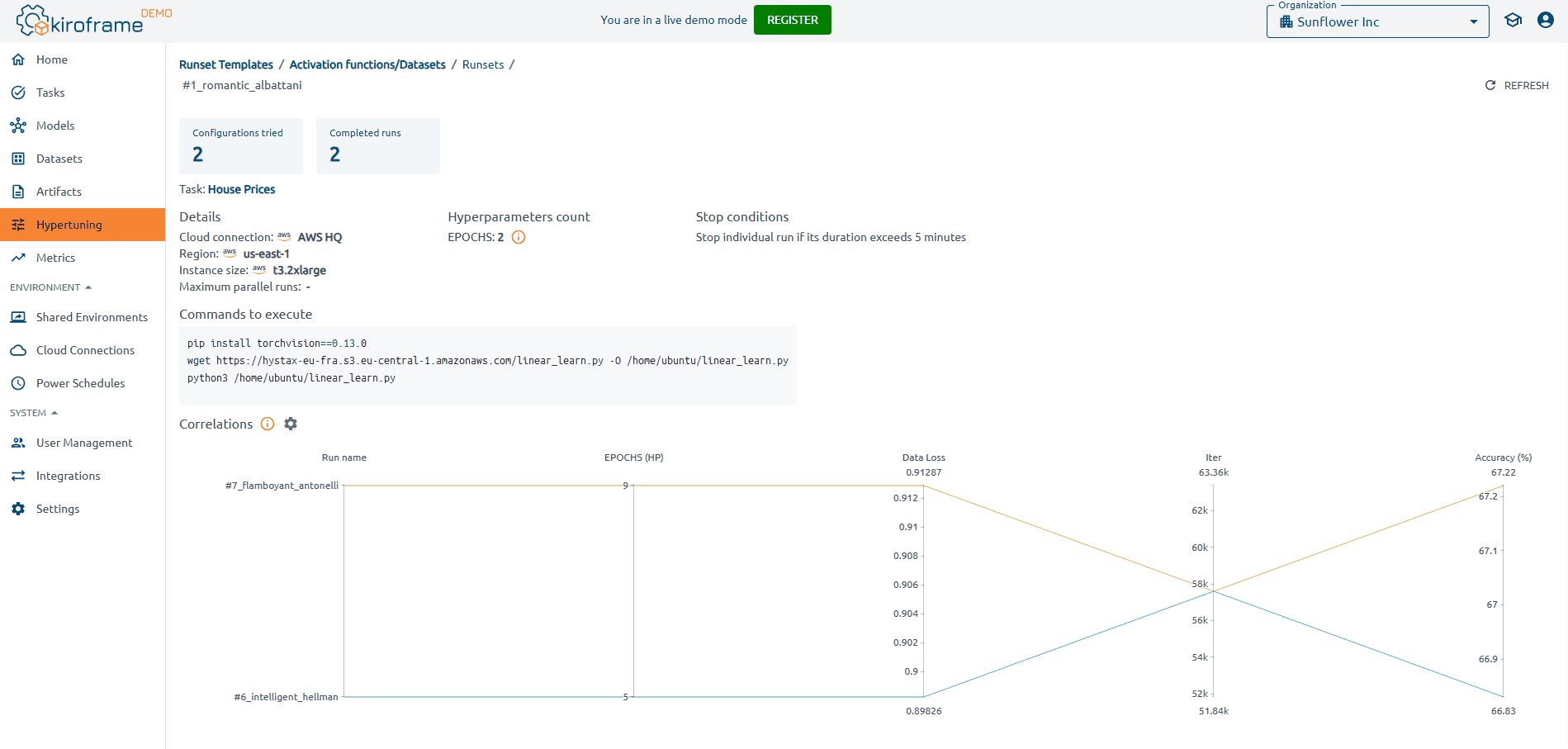
Kiroframe supports automated experiment management for both grid and random search strategies, helping teams efficiently test multiple hyperparameter distributions. With built-in visualizations and leaderboards, engineers can instantly identify top-performing configurations and ensure consistent tuning across environments.
Hyperparameter optimization methods
1. Grid search overview
Grid search is a hyperparameter tuning technique where the model is trained for every conceivable combination of hyperparameters within a predefined set.
To implement grid search, the data scientist or machine learning engineer specifies a set of potential values for each hyperparameter. The algorithm then systematically explores all possible combinations of these values. For instance, if hyperparameters involve the learning rate and the number of hidden layers in a neural network, grid search would systematically try all combinations – like a learning rate of 0.1 with one hidden layer, 0.1 with two hidden layers, etc.
The model undergoes training and evaluation for each hyperparameter combination using a predetermined metric, such as accuracy or F1 score. The combination yielding the best model performance is selected as the optimal set of hyperparameters.
2. Bayesian optimization overview
Bayesian optimization is a hyperparameter tuning approach that leverages Bayesian optimization techniques to discover a machine learning model’s optimal combination of hyperparameters.
Bayesian optimization operates by constructing a probabilistic model of the objective function, which, in this context, represents the machine learning model’s performance. This model is built based on the hyperparameter values tested thus far. The predictive model is then utilized to suggest the next set of hyperparameters to try, emphasizing expected improvements in model performance. This iterative process continues until the optimal set of hyperparameters is identified.
Key advantage:
One notable advantage of Bayesian optimization is its ability to leverage any available information about the objective function. This includes prior evaluations of model performance and constraints on hyperparameter values. This adaptability enables more efficient exploration of the hyperparameter space, facilitating the discovery of the optimal hyperparameter combination.
3. Manual search overview
Manual search is a hyperparameter tuning approach in which the data scientist or machine learning engineer manually selects and adjusts the model’s hyperparameters. Typically employed in scenarios with limited hyperparameters and a straightforward model, this method offers meticulous control over the tuning process.
In implementing the manual search method, the data scientist outlines a set of potential values for each hyperparameter. Subsequently, these values are manually selected and adjusted until satisfactory model performance is achieved. For instance, starting with a learning rate of 0.1, the data scientist may iteratively modify it to maximize the model’s accuracy.
4. Hyperband overview
Hyperband is a hyperparameter tuning method employing a bandit-based approach to explore the hyperparameter space efficiently.
The Hyperband methodology involves executing a series of “bracketed” trials. The model is also trained in each iteration using various hyperparameter configurations. Model performance is then assessed using a designated metric, such as accuracy or F1 score. The model with the best performance is chosen, and the hyperparameter space is subsequently narrowed to concentrate on the most promising configurations. This iterative process continues until the optimal set of hyperparameters is identified.
5. Random search overview
Random search is a hyperparameter tuning technique that randomly selects hyperparameter combinations from a predefined set, followed by model training using these randomly chosen hyperparameters.
To implement random search, the data scientist or machine learning engineer specifies a set of potential values for each hyperparameter. The algorithm then randomly picks a combination of these values. For instance, if hyperparameters contain the learning rate and all the applicable numbers of hidden layers in a neural network, the random search algorithm might randomly choose a learning rate of 0.1 and two hidden layers.
The model is subsequently trained and evaluated using a specified metric (e.g., accuracy or F1 score). This process is iterated a predefined number of times, and the hyperparameter combination resulting in the best model performance is identified as the optimal set.