
How to create a task in OptScale
To create a task, click the Add button to the Tasks section of the MLOps menu.

Specify a name and write a description (markdown language is supported). Set a key. Pay attention to this field. The key is a unique name that will be used later. Select the Owner from the list.

Let’s take a closer look at the Metrics section. Early-created metrics are shown on the page. This gives the option to select them right away. If you don’t have them, don’t worry you’ll be able to add them later. In the next paragraph, you’ll learn how to create and add metrics.
So, when all fields are filled in, Save the task.
Now, let’s talk about metrics.

How to add metrics and assign them to tasks in OptScale
To get to the Metrics page, pay attention to the Manage Metrics action on the Tasks page.

The page opens where you can define a set of metrics against which you should evaluate every module.
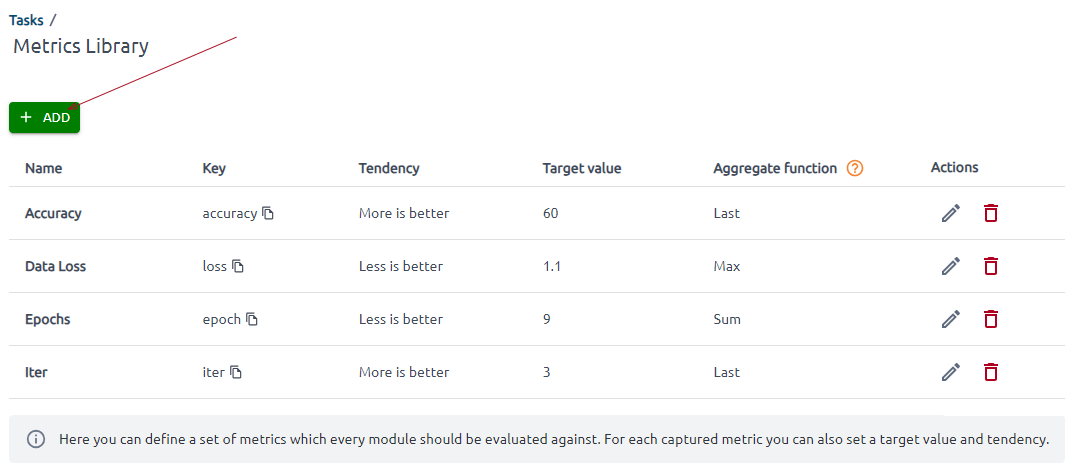
The fields on this page are intuitive, and we won’t go into detail about all of them.
Pay attention to the Key and Aggregate function fields. The Key is a metric identifier used further when you start writing code.
Please note that the metric key is an immutable value.
If a metric has multiple recorded values within one second, the aggregate function will be applied. Last, the Sum, Max, and Average functions are available.

So, now you’ve created a metric, let’s assign it to the task.

Go to the Tasks page and find the Tracked Metrics section. Click near the Tracked metrics to open the Edit Task page.

The Edit Task page opens. Switch on to assign a metric to the task. There is no need to click an additional button to save this assignment. Just go to the tasks page. It takes some time for the metric data to appear in the task.
Note that adding metrics is available at any stage.

To edit the description or owner, go to the Common tab. Save this update when finished.
Add and assign new metrics to tasks at any time you need.
How to create and run training code
When the task and metrics are created, it’s time to create and run the training code. It is not enough just to run the code. The code must be updated and run for the instance on which the training will take place. In this case, the code results will be integrated into OptScale.
Steps:
1. Install optscale_arcee
2. Instrument training code
3. Execute instrumented training code
Step 1 - Install optscale_arcee
optscale_arcee is a tool for integrating ML tasks with OptScale. It can automatically collect executor metadata from the cloud and process stats.
optscale_arcee is available on PyPI. The package must be installed at the instance on which the training will take place (i.e., the script will be executed).
Use this command to install the tool on your instance:
pip install optscale_arcee👉🏻 How to organize MLOps flow efficiently using OptScale? Learn more here → https://kiroframe.com/how-to-organize-mlops-flow-using-optscale/
Step 2 - Instrument training code
We recommend visiting the Profiling Integration page before executing the code.

Pay special attention to this page.
Some commands must be implemented into your training code to allow OptScale to get the data. Follow the steps described on this page, and you’ll succeed.

Pay your attention to them. Find the detailed description of the bolded lines in the Profiling integration side modal:
# Import re module
import torch
import os
import time
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensorimport optscale_arcee as arcee
#Import the optscale_arcee module into your training codefilename = "result.py"
epochs = int(os.getenv("EPOCHS", 5))
batch_size = 64
# Define model
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10)
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
def train(dataloader, model, loss_fn, optimizer, epoch):
size = len(dataloader.dataset)
model.train()
for batch, (x, y) in enumerate(dataloader):
x, y = x.to(device), y.to(device)
# prediction error
pred = model(x)
loss = loss_fn(pred, y)
# backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 100 == 0:
loss, current = loss.item(), batch * len(x)
arcee.send({"loss": loss, "iter": current, "epoch": epoch})
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for x, y in dataloader:
x, y = x.to(device), y.to(device)
pred = model(x)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
arcee.send({"accuracy": 100 * correct})
print(f"Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
if __name__ == "__main__":
# init arcee
with arcee.init('60e28ca7-d3cd-431f-9dec-caa9297550e5', 'key'):
#To initialize the optscale_arcee collector, you need to provide a profiling token #and a task key for which you want to collect data.
#Profiling token and key you can find on the Profiling integration side modal of the #task in the Initialization section. Profiling tokens is standard for organizations.
# The Key was specified when the task was created.

arcee.tag("Algorithm", "K-Nearest Neighbors")
arcee.tag("code_commit", "77196bfea0175ed02ab17a6797bf65ea9d0a2ba8")
arcee.model("iris_model_prod", "https://s3.amazonaws.com/ml-bucket/iris_model_prod_2.bin")
arcee.set_model_version("Version 1")
# Download training data
arcee.milestone("Download training data")
arcee.stage("preparing")
training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor(),
)
# Download test data
arcee.milestone("Download test data")
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor(),
)
arcee.milestone("create data loaders")
# Create data loaders
train_dataloader = DataLoader(training_data, batch_size=batch_size)
test_dataloader = DataLoader(test_data, batch_size=batch_size)
for x, y in test_dataloader:
print(f"Shape of x [N, C, H, W]: {x.shape}")
print(f"Shape of y: {y.shape} {y.dtype}")
break
# detect CUDA / cpu or gpu device for training.
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")
arcee.milestone("define model")
model = NeuralNetwork().to(device)
print(model)
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
arcee.stage ("calculation")
for e in range(epochs):
epoch = e + 1
arcee.milestone("Entering epoch %d" % epoch)
print(f"+Epoch {epoch}\n-------------------------------")
train(train_dataloader, model, loss_fn, optimizer, epoch)
test(test_dataloader, model, loss_fn)
arcee.milestone("Finish training")
print("+Task Done!")
torch.save(model.state_dict(), filename)
print(f"+Saved PyTorch Model State to {filename}")
Step 3 - Execute instrumented training code
Execute the instrumented script using the command
python training_code.py
If the script is run successfully, the wound will be in the “Running“ status in the corresponding task. Enjoy the results on the Tasks page!
OptScale, an open source platform with MLOps and FinOps capabilities, offers complete transparency and optimization of cloud expenses across various organizations and features MLOps tools: ML experiment tracking, ML Leaderboards, model versioning, hyperparameter tuning → OptScale demo



