Machine learning leaderboards provide a competitive framework for researchers and practitioners to assess and compare the performance of their models on standardized datasets. These platforms are essential for promoting innovation and advancing the field, offering a transparent way to evaluate the effectiveness of various algorithms and approaches. This transparency helps in understanding which methods excel in specific scenarios.
MLOps platform to automate and scale your AI development from datasets to deployment. Try it free for 14 days.
The competitive nature of machine learning leaderboards is a powerful motivation for researchers, inspiring them to push beyond current limits and develop innovative methodologies and solutions. By establishing benchmarks, these leaderboards allow for measuring progress in machine learning techniques over time, enabling researchers to identify trends and improvements in model performance through standardized comparisons. Additionally, ML Leaderboards promote community engagement, fostering a collaborative environment where practitioners can share results and techniques, ultimately enhancing collective knowledge and driving advancements in the field.
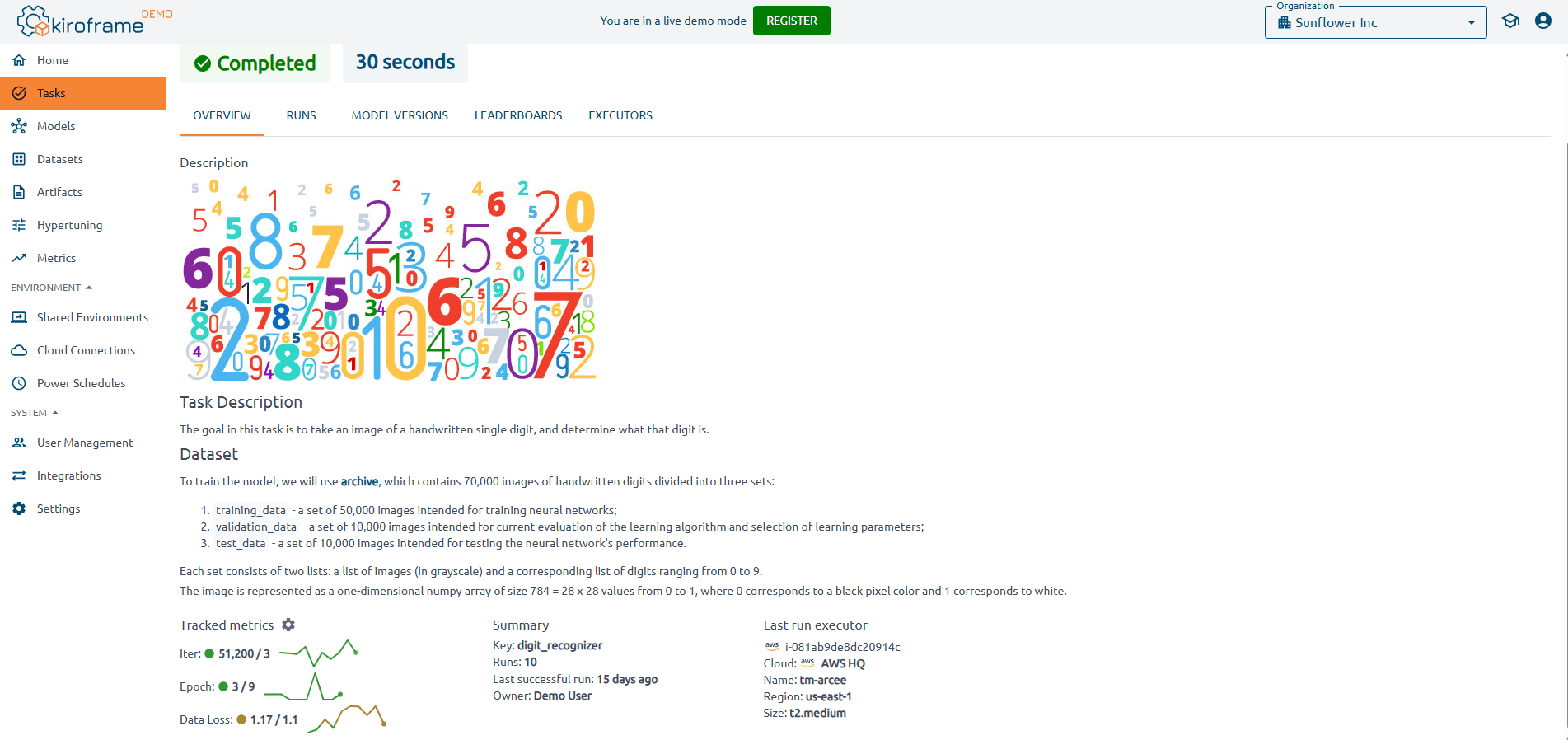
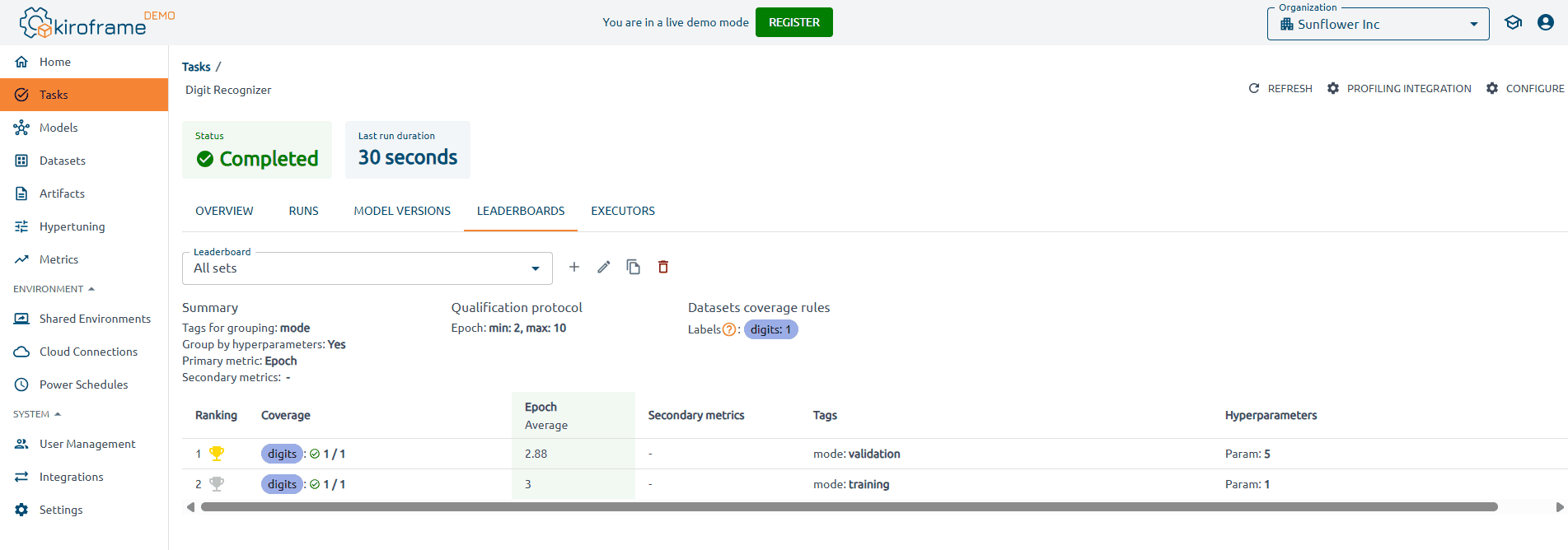
How ML Leaderboards in Kiroframe improve model tracking
In Kiroframe, leaderboards go beyond public benchmarking. They provide engineering teams with a shared space to compare experiments side by side, track custom KPIs and metrics, and link results directly to datasets, artifacts, and profiling outcomes. This ensures reproducibility and transparency, while also reducing duplication of work across teams. Unlike isolated leaderboards, Kiroframe integrates them into the complete MLOps workflow — from dataset tracking and artifact management to profiling and environment sharing — making them a practical tool for collaboration, decision-making, and accelerating model development in production settings.
Challenges of ML Leaderboards
While ML Leaderboards offer numerous benefits, they also come with several inherent challenges:
Exploiting weaknesses: Some users may leverage gaps in the evaluation process to achieve higher rankings without enhancing their model’s capabilities.
Overfitting: Participants may excessively optimize their models for the specific leaderboard dataset, diminishing performance on new, unseen data.
Machine learning leaderboards play a vital role in the field’s progress by providing a competitive and organized platform for model assessment. They drive innovation, enable benchmarking, and foster community collaboration. However, addressing these challenges is crucial to ensuring that the advantages of leaderboards are fully harnessed.
Essential key performance metrics in machine learning leaderboards
Machine learning leaderboards are vital for evaluating and comparing model performance, as they rank models based on key performance metrics. These metrics are essential for understanding how well models perform specific tasks and can significantly shape participants’ strategies.
Here are some critical metrics commonly utilized in machine learning leaderboards:
Area under the ROC Curve (AUC)
AUC assesses model performance across various classification thresholds, plotting the True Positive Rate against the False Positive Rate. This metric provides a comprehensive view of a model’s ability to differentiate between classes, with values ranging from 0 to 1 – where 0.5 indicates random guessing.
F1-score
The F1-score is the harmonic mean of precision and recall, providing a balanced perspective on both metrics. It is beneficial when working with imbalanced datasets. The formula for the F1 score is:
Precision measures the ratio of accurate positive predictions to the total predicted positives, indicating the quality of the model’s optimistic predictions. This evaluation is crucial in scenarios where false positives can lead to significant consequences, as it assesses the accuracy of these predictions. The formula for precision is:
Recall measures a model’s ability to identify all relevant instances and is especially important when missing a positive instance can have severe consequences. The formula for the recall is:
Accuracy provides an overall measure of how often the model is correct across all predictions. This metric is particularly relevant in tasks such as intrusion detection, where both benign and malicious cases must be accurately assessed. The formula for accuracy is:
Accuracy = Number of Correct Predictions / Total Number of Predictions
Mean Reciprocal Rank (MRR)
MRR is essential for search and recommendation systems. It calculates the average of the reciprocal ranks of the first relevant item retrieved for a set of queries. This metric evaluates how effectively a system ranks relevant items at the top.
These metrics are crucial for evaluating model performance and guiding improvements and innovations in machine learning algorithms. By understanding and utilizing these metrics, researchers and practitioners can better navigate the complexities of model evaluation and selection, ultimately driving the field forward.
How Kiroframe uses key performance metrics in ML Leaderboards
Kiroframe leverages essential performance metrics as the foundation of its ML leaderboards, turning raw numbers into actionable insights. Models can be ranked and compared side by side, with results linked directly to datasets, artifacts, and profiling data. This ensures that every metric is not just a score but is reproducible, traceable, and transparent across the team. Engineering teams can also customize leaderboards with the KPIs most relevant to their use case, monitor progress across experiments, and collaborate more effectively. By embedding these metrics into the broader MLOps workflow, Kiroframe transforms leaderboards into a practical tool for decision-making, model selection, and accelerating production-ready AI.
In conclusion
Machine learning leaderboards are essential for evaluating and comparing model performance, helping participants fine-tune their strategies. They rank models based on key performance metrics, such as accuracy, precision, and recall, providing insights into how well models perform specific tasks. These metrics are crucial in understanding model efficiency and effectiveness in real-world applications.
We use cookies to ensure that we give you the best experience on our website. If you continue to use this site we will assume that you are happy with it.